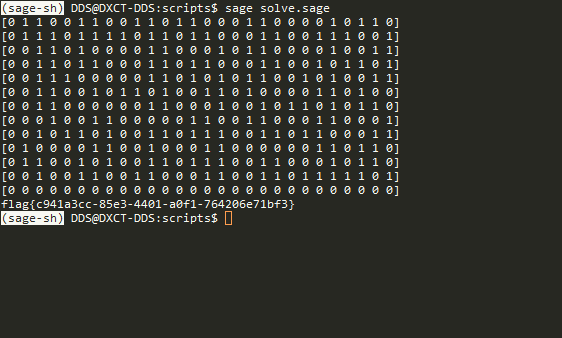
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
|
def _GetRandomPermutationMatrix(n):
# Set up the permutation matrix
rng = range(n); P = matrix(GF(2),n);
for i in range(n):
p = floor(len(rng)*random());
P[i,rng[p]] = 1; rng=list(rng[:p])+list(rng[p+1:]);#此处需要加list()转换,python3与python2不同
return copy(P);
def _GetColumnVectorWeight(n):
weight = 0;
for i in range(n.nrows()):
if n[i,0] == 1:
weight = weight+1;
return weight;
def SternsAlgorithm(H, w, p, l):
H_Stern = copy(H);
codeword_found = false;
#Begin Stern's Algorithm for finding a weight-w codeword of the code generated by H
while (not codeword_found):
n_k = H_Stern.nrows();
k = H_Stern.ncols() - n_k;
I_n = identity_matrix(n_k);
singular = true;
P_Stern = 0; #initialize the permutation matrix
H_Prime = 0; #initialize the permuted parity-check matrix
#Search for (n-k) linearly independent columns.
while singular:
P_Stern = _GetRandomPermutationMatrix(H_Stern.ncols());
H_Prime = H_Stern*P_Stern; #permute the matrix
H_Prime.echelonize(); #row-reduce the first n-k columns
#If the selected n-k columns do not row-reduce, select a different combination of columns
if H_Prime.submatrix(0,0,n_k,n_k) == I_n:
singular = false;
#initialize and populate the set of n_k-l rows that will be deleted from H_Prime to leave l rows
Z = set();
while len(Z) < n_k-l:
Z.add(randint(0,n_k-1)); #H.nrows()=n_k, but indices start at 0
Z = list(Z); Z.sort(); #Make Z a sorted list
#A copy of H_Prime with only the l selected rows (in Z) remaining
H_Prime_l = copy(H_Prime);
H_Prime_l = H_Prime_l.delete_rows(Z);
#Initialize the sets of indices of the columns of H_Prime_l
X_Indices = list(); Y_Indices = list();
#Assign a column indices to X or Y randomly (50/50 chance)
for i in range(k):
if randint(0,1)==0:
X_Indices.append(i+n_k);
else:
Y_Indices.append(i+n_k);
#Generate the size-p subsets of X and Y,
#and initialize the lists containing each subset's sum
Subsets_of_X_Indices = Subsets(X_Indices,p);
Subsets_of_Y_Indices = Subsets(Y_Indices,p);
pi_A = list();
pi_B = list();
#Calculate pi(A) for each subset of X
for i in range(Subsets_of_X_Indices.cardinality()):
column_sum = 0;
for j in range(p):
column_sum = column_sum + H_Prime_l.submatrix(0,Subsets_of_X_Indices[i][j],H_Prime_l.nrows(),1);
pi_A.append(column_sum);
#Calculate pi(B) for each subset of Y
for i in range(Subsets_of_Y_Indices.cardinality()):
column_sum = 0;
for j in range(p):
column_sum = column_sum + H_Prime_l.submatrix(0,Subsets_of_Y_Indices[i][j],H_Prime_l.nrows(),1);
pi_B.append(column_sum);
weight_w_codeword = 0; #initialize the codeword
#Check each pi(A) value against every pi(B) value to check for collisions
for i in range(len(pi_A)):
for j in range(len(pi_B)):
#If a collision occurs, calculate the n-k - bit vector computed by summing the
#entirety of the columns whose indices are in A U B
if pi_A[i] == pi_B[j]:
sum = 0; #initialize the sum vector
for k in (Subsets_of_X_Indices[i]):
sum = sum + H_Prime.submatrix(0,k,H_Prime.nrows(),1);
for k in (Subsets_of_Y_Indices[j]):
sum = sum + H_Prime.submatrix(0,k,H_Prime.nrows(),1);
if _GetColumnVectorWeight(sum) == (w-2*p):
codeword_found = true;
#Since the sum vector has the appropriate weight, the codeword of weight w can now be calculated
#Initialize the codeword
weight_w_codeword = matrix(GF(2),H_Stern.ncols(),1);
#Mark the appropriate positions of the codeword as ones
for index in range(n_k):
if sum[index,0]==1:
weight_w_codeword[index,0] = 1;
for k in Subsets_of_X_Indices[i]:
weight_w_codeword[k,0] = 1;
for k in Subsets_of_Y_Indices[j]:
weight_w_codeword[k,0] = 1;
#Undo the permuting done when selecting n-k linearly independent columns
weight_w_codeword = weight_w_codeword.transpose()*(~P_Stern);
return copy(weight_w_codeword);
|